1.14. 半监督学习
校验者: @STAN,废柴0.1 @Loopy @N!no 翻译者: @那伊抹微笑
半监督学习 是指训练数据中一些样本数据没有标签的情况。sklearn.semi_supervised 中的半监督估计器,能够利用这些附加的未标记数据来更好地捕获底层数据分布的形状,并将其更好地类推广到新的样本。当训练数据中有非常少量的有标签的点和大量的无标签的点时,这些算法可以表现良好。
y 中含有未标记的数据
- 在使用
fit方法训练数据时,将标识符分配给无标签和有标签的点是尤其重要的。此实现使用的标识符是整数值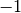 。
。
1.14.1. 标签传播
标签传播表示半监督图推理算法的几个变体。
该模型的一些特性如下:
- 可用于分类和回归任务
- 使用内核方法将数据投影到备用维度空间
scikit-learn 提供了两种标签传播模型: LabelPropagation 和 LabelSpreading 。 两者都通过在输入数据集中的所有项目上构建相似图来进行工作。
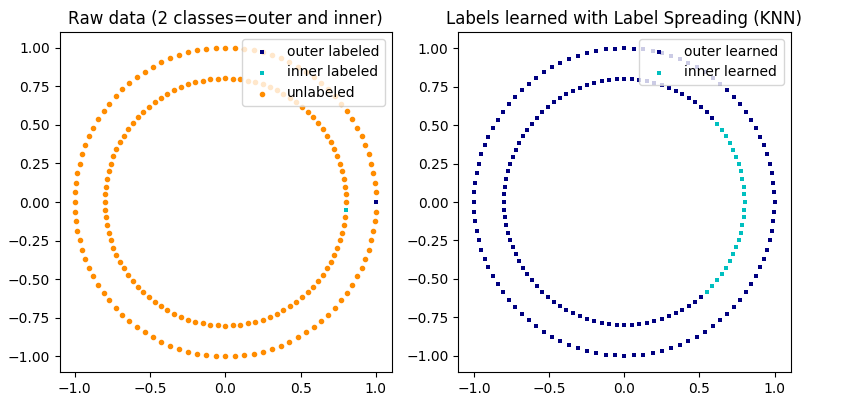
标签传播说明: 无标签的观察值结构与类结构一致,因此可以将类标签传播到训练集的无标签的观察值上。
LabelPropagation 和 LabelSpreading 在对图形的相似性矩阵以及对标签分布的夹持效应(clamping effect)方面的修改不太一样。 夹持效应允许算法在一定程度上改变真实标签化数据的权重。 LabelPropagation 算法执行输入标签的全加持(hard clamping),这意味着 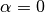 。夹持因子可以不一定很严格。例如
。夹持因子可以不一定很严格。例如 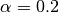 意味着我们将始终保留原始标签分配的 80%,但该算法可以将其分布的置信度改变在 20% 以内。
意味着我们将始终保留原始标签分配的 80%,但该算法可以将其分布的置信度改变在 20% 以内。
LabelPropagation 使用原始相似性矩阵从未修改的数据来构建。 LabelSpreading 最小化具有正则化属性的损耗函数,因此它通常更适用于噪声数据。该算法在原始图形的修改版本上进行迭代,并通过计算 normalized graph Laplacian matrix(归一化图拉普拉斯矩阵)来对边缘的权重进行归一化。 这个过程也被用于 Spectral clustering。
标签传播模型有两种内置的核函数。核的选择会影响算法的可扩展性和性能。 以下是可用的核:
- rbf (
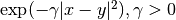 ) —
) — 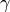 通过关键字 gamma 来指定。
通过关键字 gamma 来指定。 - knn (
![1[x' \in kNN(x)]](../img/6db85b1ad926d9ad860d58629ff5f235.jpg) ) —
) — 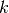 通过关键字 n_neighbors 来指定。
通过关键字 n_neighbors 来指定。
RBF 核将产生一个全连接的图形,它通过密集矩阵在内存中表示。这个矩阵可能非常大,加之算法每次迭代执行全矩阵乘法的计算成本,我们可能会有特别长的运行时间。另一方面,KNN 核能够产生更多的内存友好的稀疏矩阵,这可以大幅度的减少运行时间。
示例
- Decision boundary of label propagation versus SVM on the Iris dataset
- Label Propagation learning a complex structure
- Label Propagation digits: Demonstrating performance
- Label Propagation digits active learning
参考资料 * [1] Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux. In Semi-Supervised Learning (2006), pp. 193-216 * [2] Olivier Delalleau, Yoshua Bengio, Nicolas Le Roux. Efficient Non-Parametric Function Induction in Semi-Supervised Learning. AISTAT 2005 http://research.microsoft.com/en-us/people/nicolasl/efficient_ssl.pdf
