频谱共聚算法演示
翻译者:@N!no 校验者:待校验
这个例子演示了如何使用谱协聚类算法生成数据集并对其进行双聚类处理。
数据集是使用 make_biclusters 函数生成的,该函数创建一个小值矩阵,并将大值植入双聚类。然后将行和列打乱并传递给光谱协聚算法。通过重新排列变换后的矩阵可以使双聚类连续,这展示出该算法找到双聚类的准确性。
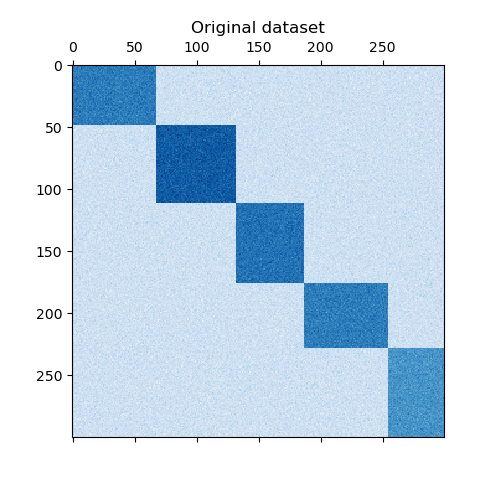
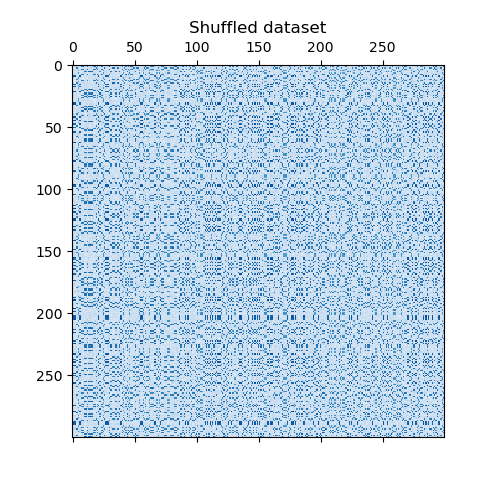
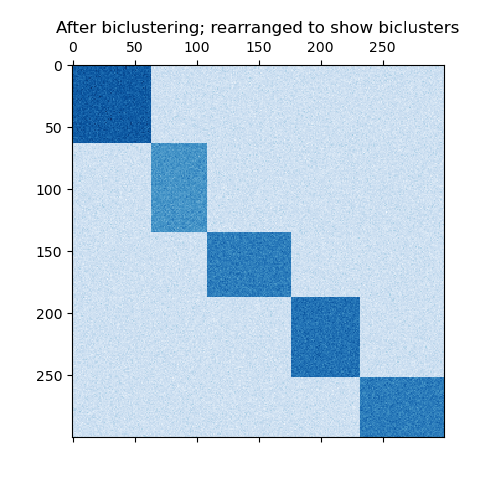
consensus score: 1.0
print(__doc__)
# Author: Kemal Eren <kemal@kemaleren.com>
# License: BSD 3 clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_biclusters
from sklearn.cluster import SpectralCoclustering
from sklearn.metrics import consensus_score
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5,
shuffle=False, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
# 打乱聚类的位置
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,
(rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.3f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
